 NVIDIA just launched the TU102/TU104 (GeForce RTX 2080ti/2080), first GPUs based on the Turing architecture. This new architecture brings hardware ray-tracing acceleration, as well as many other new and really cool graphics features. A good high-level overview of the architecture and new graphics features can be found in the Turing Architecture whitepaper as well as this blog post. Most of these features are exposed through both Vulkan and OpenGL extensions, and I will quickly go through each of them in this post. A big thanks to the many people at NVIDIA who worked hard to provide us with these extensions !
NVIDIA just launched the TU102/TU104 (GeForce RTX 2080ti/2080), first GPUs based on the Turing architecture. This new architecture brings hardware ray-tracing acceleration, as well as many other new and really cool graphics features. A good high-level overview of the architecture and new graphics features can be found in the Turing Architecture whitepaper as well as this blog post. Most of these features are exposed through both Vulkan and OpenGL extensions, and I will quickly go through each of them in this post. A big thanks to the many people at NVIDIA who worked hard to provide us with these extensions !Most features split into a Vulkan or OpenGL -specific extension (GL_*/VK_*), and a GLSL or SPIR-V shader extension (GLSL_*/SPV_*).
Ray-Tracing Acceleration
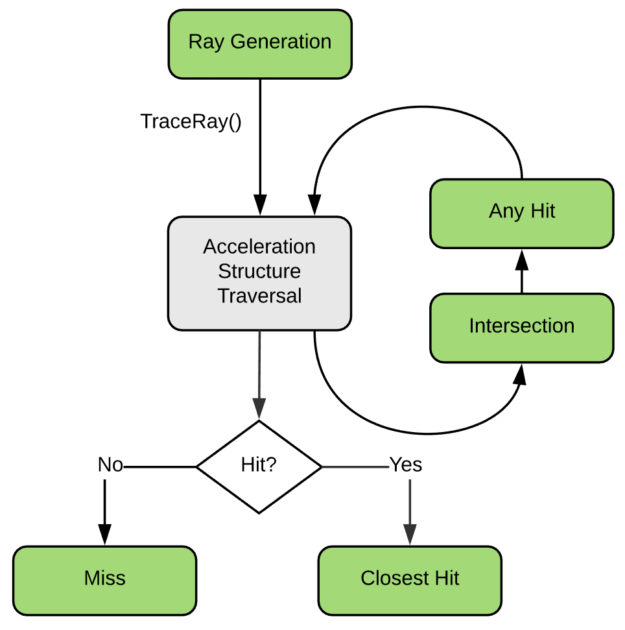 Turing brings hardware acceleration for ray-tracing through dedicated units called RT cores. The RT cores provide BVH traversal as well as ray-triangle intersection. This acceleration is exposed in Vulkan through a new ray-tracing pipeline, associated with a series of new shader stages. This programming model maps the DXR (DirectX Ray-Tracing) model, which is quickly described in this blog post, and this blog post details the Vulkan implementation.
Turing brings hardware acceleration for ray-tracing through dedicated units called RT cores. The RT cores provide BVH traversal as well as ray-triangle intersection. This acceleration is exposed in Vulkan through a new ray-tracing pipeline, associated with a series of new shader stages. This programming model maps the DXR (DirectX Ray-Tracing) model, which is quickly described in this blog post, and this blog post details the Vulkan implementation.
A GTC 2018 presentation about Vulkan Ray-Tracing can also be found there: http://on-demand.gputechconf.com/gtc/2018/video/S8521/ (Slides here).
This blog post details
This blog post details
Mesh Shading

This is a new programmable geometry pipeline which replaces the traditional VS/HS/DS/GS pipeline with basically a Compute-based programming model. This new pipeline is based on two shader stages, a Task Shader and a Mesh Shader (separated by an expansion stage), which are used to ultimately generate a compact mesh description called a Meshlet. A Meshlet is a mini indexed geometry representation which is maintained on chip and is directly fed to the rasterizer for consumption. This exposes a very flexible and very efficient model with Compute Shader features and generic cooperative thread groups (workgroups, shared memory, barrier synchronizations...). Applications are endless, and this can for instance be used to implement efficient culling or LOD schemes, or perform procedural geometry generation.
Many details can be found in this excellent blog post by Christoph Kubisch: https://devblogs.nvidia.com/introduction-turing-mesh-shaders/
As well as in his Siggraph 2018 presentation: http://on-demand.gputechconf.com/siggraph/2018/video/sig1811-3-christoph-kubisch-mesh-shaders.html
A full OpenGL sample code which implements a compute-based adaptive tessellation technique can also be found there: https://github.com/jdupuy/opengl-framework/tree/master/demo-isubd-terrain
 This is a very powerful hardware feature which allows the application to dynamically control the number of fragment shader invocations (independently of the visibility rate) and vary this shading rate across the framebuffer. The shading rate is controlled using a texture image ("Shading Rate Image", 8b/texel) where each texel specifies an independent shading rate for blocks of 16x16 pixels. The rate is actually specified indirectly
using 8b indices into a palette which is specified per-viewport and stores the actual
shading rate flags.
This is a very powerful hardware feature which allows the application to dynamically control the number of fragment shader invocations (independently of the visibility rate) and vary this shading rate across the framebuffer. The shading rate is controlled using a texture image ("Shading Rate Image", 8b/texel) where each texel specifies an independent shading rate for blocks of 16x16 pixels. The rate is actually specified indirectly
using 8b indices into a palette which is specified per-viewport and stores the actual
shading rate flags.
The GLSL extensions also exposes intrinsics allowing fragment shaders to read the effective fragment size in pixels (gl_FragmentSizeNV) as well as the number of fragment shader invocation for a fully covered pixel (gl_InvocationsPerPixelNV). This opens the road to many new algorithms and more efficient implementations of optimized shading rate techniques, like Foveated Rendering, Lens Adaptation (for VR), Content or Motion Adaptive Shading.
More info on Variable Rate Shading in this blog post: https://devblogs.nvidia.com/turing-variable-rate-shading-vrworks/



A full OpenGL sample code which implements a compute-based adaptive tessellation technique can also be found there: https://github.com/jdupuy/opengl-framework/tree/master/demo-isubd-terrain
Variable Rate Shading
- VK_NV_shading_rate_image / GL_NV_shading_rate_image (GLSL_NV_shading_rate_image / SPV_NV_shading_rate)
 This is a very powerful hardware feature which allows the application to dynamically control the number of fragment shader invocations (independently of the visibility rate) and vary this shading rate across the framebuffer. The shading rate is controlled using a texture image ("Shading Rate Image", 8b/texel) where each texel specifies an independent shading rate for blocks of 16x16 pixels. The rate is actually specified indirectly
using 8b indices into a palette which is specified per-viewport and stores the actual
shading rate flags.
This is a very powerful hardware feature which allows the application to dynamically control the number of fragment shader invocations (independently of the visibility rate) and vary this shading rate across the framebuffer. The shading rate is controlled using a texture image ("Shading Rate Image", 8b/texel) where each texel specifies an independent shading rate for blocks of 16x16 pixels. The rate is actually specified indirectly
using 8b indices into a palette which is specified per-viewport and stores the actual
shading rate flags.
Not only the feature allows to vary the MSAA shading rate per-pixel (allowing 1x,4x,8x, and now even 16x SSAA, but with a maximum of 8x depth test and color storage), but it also allows to drop the shading rate below one invocation per-pixel, down to one invocation per block of 4x4 pixels (through one per 1x2, 2x1, 2x2, 2x4 and 4x2 pixels) and even zero invocation.
The GLSL extensions also exposes intrinsics allowing fragment shaders to read the effective fragment size in pixels (gl_FragmentSizeNV) as well as the number of fragment shader invocation for a fully covered pixel (gl_InvocationsPerPixelNV). This opens the road to many new algorithms and more efficient implementations of optimized shading rate techniques, like Foveated Rendering, Lens Adaptation (for VR), Content or Motion Adaptive Shading.
Exclusive Scissor Test
This adds a second per-viewport scissor test, which culls fragments *inside* (exclusive) the specified rectangle, unlike the standard scissor test which culls *outside* (inclusive). This can be used for instance to implement more efficient multi-resolution foveated-rendering techniques (in conjunction with Variable Rate Shading), where raster passes fill concentric strips of pixels by enabling both inclusive and exclusive scissor tests.
Texture Access Footprint
- VK_NV_shader_image_footprint / GL_NV_shader_texture_footprint (GLSL_NV_shader_texture_footprint / SVP_NV_shader_image_footprint)

These extensions expose a set of GLSL (and SPIR-V) query functions which report the texture-space footprints of texture lookups, ie. some data identifying the set of all texels that may be accessed in order to return a filtered result for the corresponding texture accesses (which can use anisotropic-filtering and potentially cover large footprints). Footprints are returned and represented as an LOD value, an anchor point and a 64-bit bitfield where each bit represents coverage for a group of neighboring texel (in 2D, group granularity can range from 2x2 to 256x256 texels).
This is actually an important component for implementing multi-pass decoupled and texture-space shading pipelines, where a restricted set of actually visible pixels must be determined in order to efficiently perform shading in a subsequent pass.
Derivatives in Compute Shader
- VK_NV_compute_shader_derivatives / GL_NV_compute_shader_derivatives (GLSL_NV_compute_shader_derivatives / SPV_NV_compute_shader_derivatives)

These extensions bring Compute even closer to Graphics by adding support for Quad-based derivatives in Compute Shaders, using the x and y coordinates of the local workgroup invocation ID. This allows Compute Shaders to use both built-in derivative functions like dFdx(), as well as texture lookup functions using automatic LOD computation, and the texture level of detail query function (textureQueryLod()).
Two layout qualifiers are provided allowing to specify Quad arrangements based on a linear index or 2D indices.
Two layout qualifiers are provided allowing to specify Quad arrangements based on a linear index or 2D indices.
Shader Subgroup Operations
- VK_NV_shader_subgroup_partitioned / GL_NV_shader_subgroup_partitioned (SPV_NV_shader_subgroup_partitioned)
These shader extensions provide a series of ballot-based partitioning and scan/reduce operations which operate on "subgroups" of shader invocations. This can be used for instance to implement clustering and de-duplication operations on sets of values distributed among different shader invocations.
Barycentric Coordinates and manual attributes interpolation
- VK_NV_fragment_shader_barycentric / GL_NV_fragment_shader_barycentric (GLSL_NV_fragment_shader_barycentric / SPV_NV_fragment_shader_barycentric)
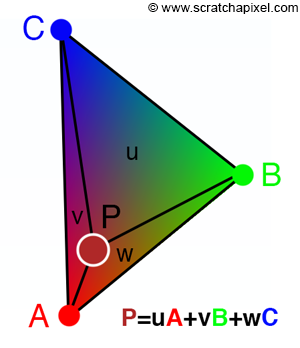 |
| Illustration courtesy of Jean-Colas Prunier, https://www.scratchapixel.com/ |
This feature exposes barycentric coordinates as Fragment Shader input in GLSL (and SPIR-V), and provides the ability for a Fragment Shader to directly fetch raw per-vertex values in order to perform manual barycentric interpolation.
A three-component vector built-in input gl_BaryCoordNV provides
perspective-corrected barycentric coordinates (gl_BaryCoordNoPerspNV for non- perspective-correct). Per-vertex inputs use the same brackets array syntax as for Tesselation and Geometry Shader inputs, and a pervertexNV qualifier is added to identify input blocs and variables which read raw per-vertex values from the vertices of the original primitive.
This feature potentially allows more efficient data passing to the Fragment Shader using compact or compressed data formats for instance. It could also allow interpolation from vertex values fetched directly from memory, user defined interpolations, or various reconstructions and computations using raw attributes accessed from the three vertices.
Ptex Hardware Acceleration

An corner-sampled image has texels centered on integer coordinates instead of being halfway, which allows edge sampling coordinates to filter to the exact texels on the edge of the texture. This facilitates implementing Ptex (Per-face Texture [Burley and Lacewell 2008], cf. https://developer.nvidia.com/sites/default/files/akamai/gamedev/docs/Borderless%20Ptex.pdf) texturing in real-time applications by providing proper filtering and interpolation. Ptex uses separate textures for each face of a subdivision surface or polygon mesh, and sample locations are placed at pixel corners, maintaining continuity between adjacent patches by duplicating values along shared edges.
Representative Fragment Test
This extension has been designed to allow optimizing occlusion queries techniques which rely on per-fragment recording of visible primitives. It allows the hardware to stop generating fragments and stop emitting fragment shader invocations for a given primitive as long as a single fragment has passed early depth and stencil tests. This reduced subset of fragment shader invocation can then be used to record visible primitives in a more performant way. This is only a performance optimization, and no guarantee is given on the number of discarded fragments and consequently the number of fragment shader invocations that will actually be executed.
Multi-View Rendering
Pascal Simultaneous Multi-Projection (SMP) and stereo view features allowed broadcasting the same geometric data for rasterization to multiple views (up to 2) and viewports (up to 16) with very limited possibilities of per-view (and viewport) variations (an horizontal position offset per-view and xyz swizzle per-viewport + viewport attributes). Turing generalizes and improves over this feature by allowing to specify fully independent per-view attribute values (including vertex positions) and exposes up to 4 views. No new extension is provided, but the feature is exposed transparently as an optimization to the existing standardized Vulkan VK_KHR_multiview and OpenGL GL_OVR_multiview extensions.
More info on Multi-View Rendering in this bog post: https://devblogs.nvidia.com/turing-multi-view-rendering-vrworks/
More info on Multi-View Rendering in this bog post: https://devblogs.nvidia.com/turing-multi-view-rendering-vrworks/